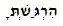Your test document seems to display ok on Word 2007, but when I copy and paste the text from it to the BabelPad editor, it gets displayed wrong the same way as in your picture. When I use the BabelPad command Convert → Normalization Form → To NFC, the display gets fixed.
It seems that the problem is not with precomposed characters like U+FB32 HEBREW LETTER GIMEL WITH DAGESH as such, but in conjunction with an additional combining mark like U+05B7 HEBREW POINT PATAH after it. Some programs cannot deal with such combinations, even though they can handle a fully decomposed form (base letter followed by two combining marks).
It is impossible (and probably irrelevant) to know how the character combinations got into the file. They are valid Unicode data, but unnormalized, and normalization would presumably fix the problem. It seems that you could really use any of the Unicode normalization forms here, but NFC is often favored for general reasons.
As far as I know, Word has no tools for normalization, so you would need to use external tools for it. BabelPad would be suitable for plain text, but I don’t know how well it handles large files, and you probably have some formatting you need to preserve. So maybe you could save the file as HTML, normalize the data to NFC in BabelPad, and then open the so modified HTML file in Word. (I first thought of using RTF instead of HTML, but Word seems to generate RTF that does not contain the actual Hebrew characters but some escape notations.)